
AI Careers in 2025+
Thank you for everyone who was able to join my Maven Talk!

For everyone who couldn’t make it to the session or even if you did and wanted to have access to the material, here is a summary of the session to quickly skim what we talked about.
Although the video recording for the session couldn’t be processed coz of some technical issues but I hope this descriptive post will suffice. I am planning to do a follow up AMA session to go into the reading material for the same, do let me know if you want me to start with a particular role first.
The AI job market is growing over 40% year-over-year. But here's the catch: it's not just research roles anymore.
2024 marked a turning point: the AI talent bottleneck isn’t in model training. It's in scaling, deploying, and integrating AI into production systems. If you're an engineer, data scientist, or even a PM, you're already seeing this shift in job postings, skill requirements, and team structures.
In this post, I’ll break down:
What’s really happening in AI hiring
Which roles are at risk (and which are emerging)
The four roles that will dominate AI careers in 2025+
Exactly how to prepare for them
What the Hell is Going On?
AI is no longer just research-driven but companies need operational roles to run, scale, and deliver AI.
AI hiring is exploding (40% YoY growth). Business Insider reports that companies are already hiring aggressively for inference, deployment, and systems roles outside core research.
Inference is the bottleneck. Companies from startups to OpenAI and Nvidia can’t hire fast enough for engineers who understand GPU-level performance, inference frameworks (vLLM, TensorRT-LLM), and distributed serving.
Pedigree is dead, skills are king. These jobs aren’t filled based on academic credentials but they're filled based on whether you can tune a KV cache, debug CUDA kernels, or build embedding pipelines.
TL;DR: The bottleneck has moved from "training models" to "scaling them in production."
Is My Role at Risk?
Traditional roles are evolving fast:
Data Scientists: Startups don’t want incremental optimization. Instead, they want engineers who can prep data for retrieval (RAG), build eval sets, and chunk intelligently.
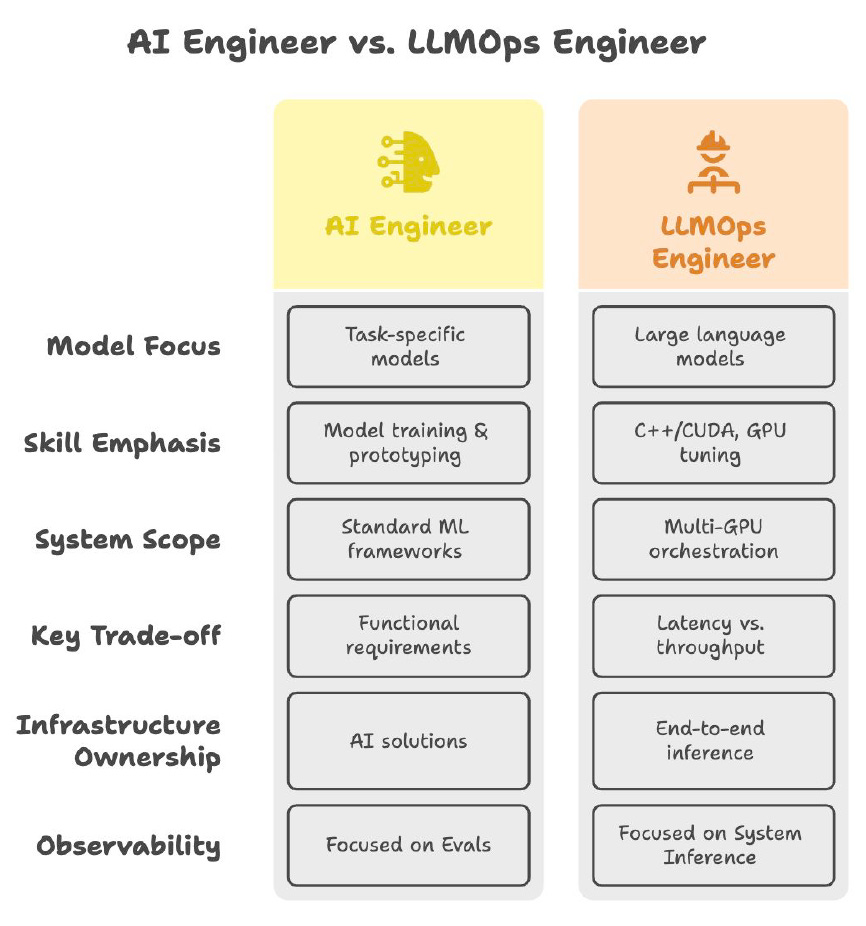
ML Engineers: Being an "ML Engineer" who only trains models is outdated. The new "AI Engineer" role focuses on integrating APIs, optimizing inference, and deploying large models.
MLOps Engineers: Familiarity with CI/CD pipelines isn’t enough. LLMOps engineers need GPU-level tuning, Ray orchestration, and deep understanding of latency-sensitive inference.
Product Managers: Enter the Forward-Deployed Engineer (FDE): half PM, half engineer. This role embeds with clients, builds real-world AI solutions, and ships fast.
Emerging Skill Gaps:
Pandas/SQL → Chunking & embedding pipelines
Model training → LLM integration & eval loops
CI/CD → GPU orchestration & inference debugging
Slides & strategy → Building & shipping GenAI systems
The Four Roles of 2025 and Beyond
Here are the four roles companies are hiring for NOW (even if they use different titles):
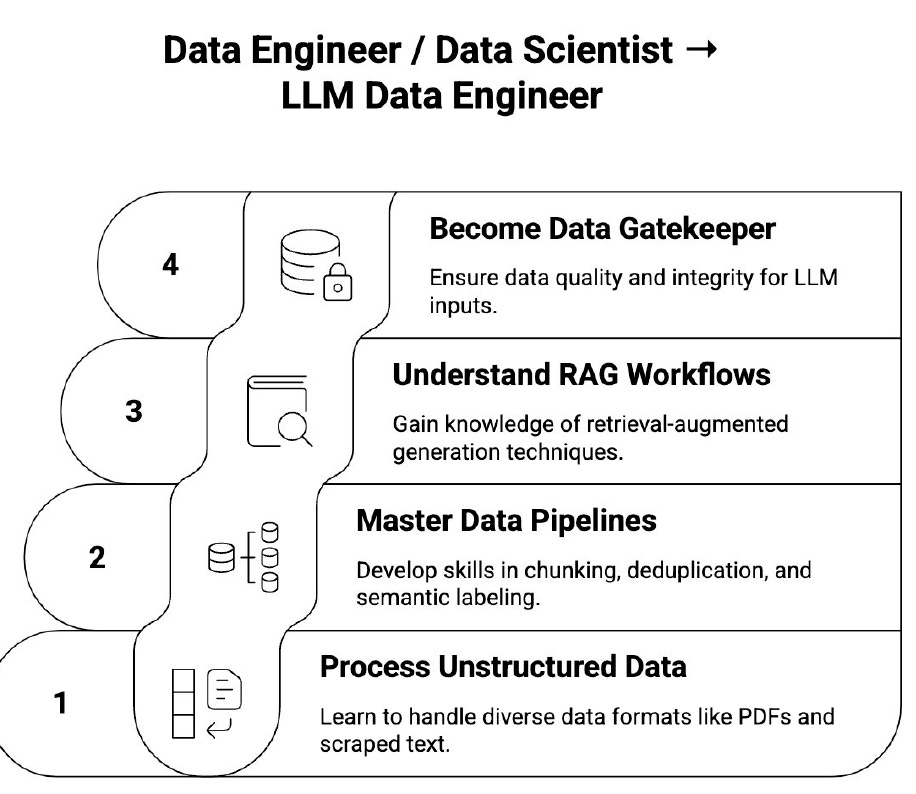
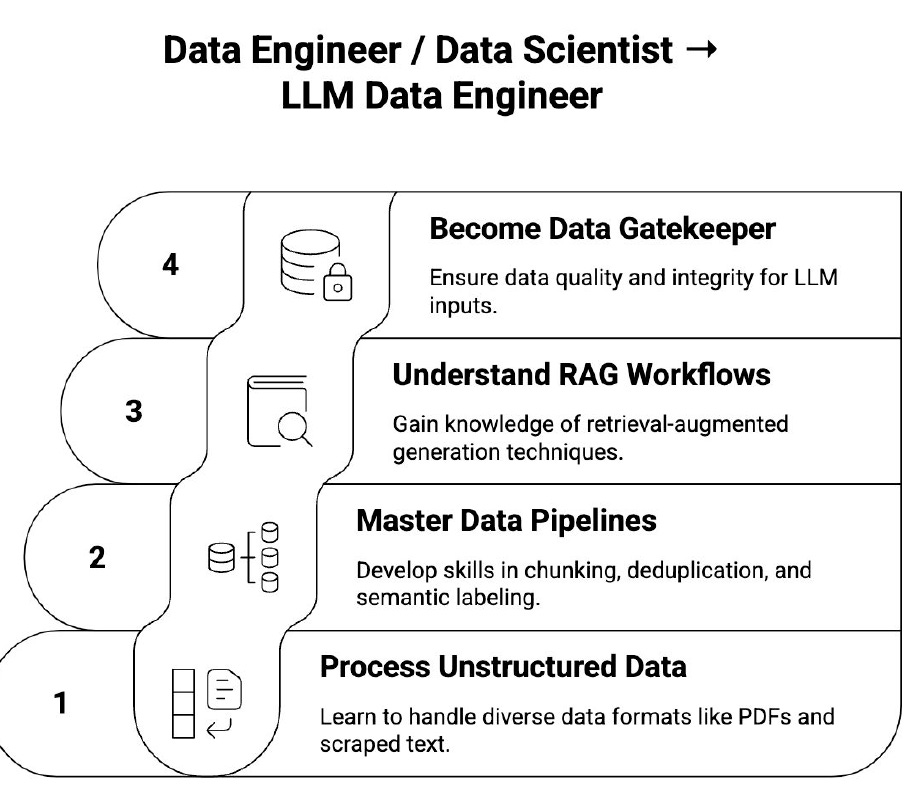
LLM Data Engineer
Skills: Chunking, embedding pipelines, RAG prep, deduplication, semantic data quality.
Why: Companies need better data flow for inference, not more models.
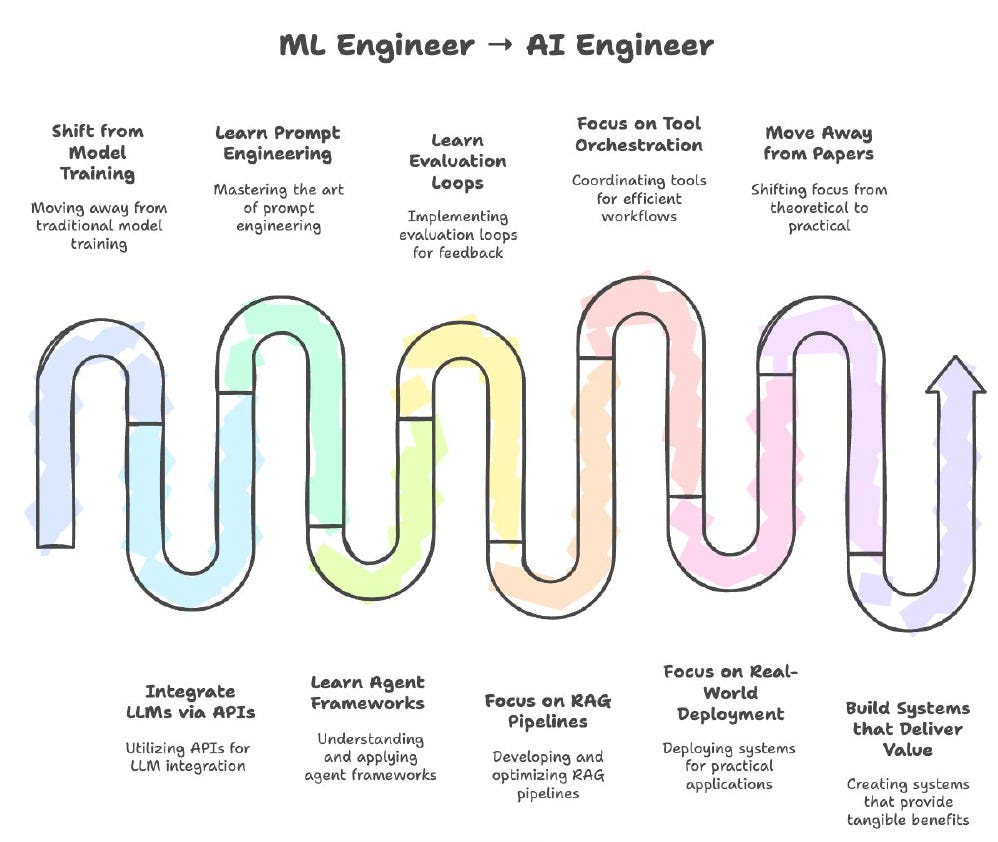
AI Engineer
Skills: Integrating APIs, inference optimization, eval loops, multi-agent orchestration.
Why: The bridge between research prototypes and production AI systems.

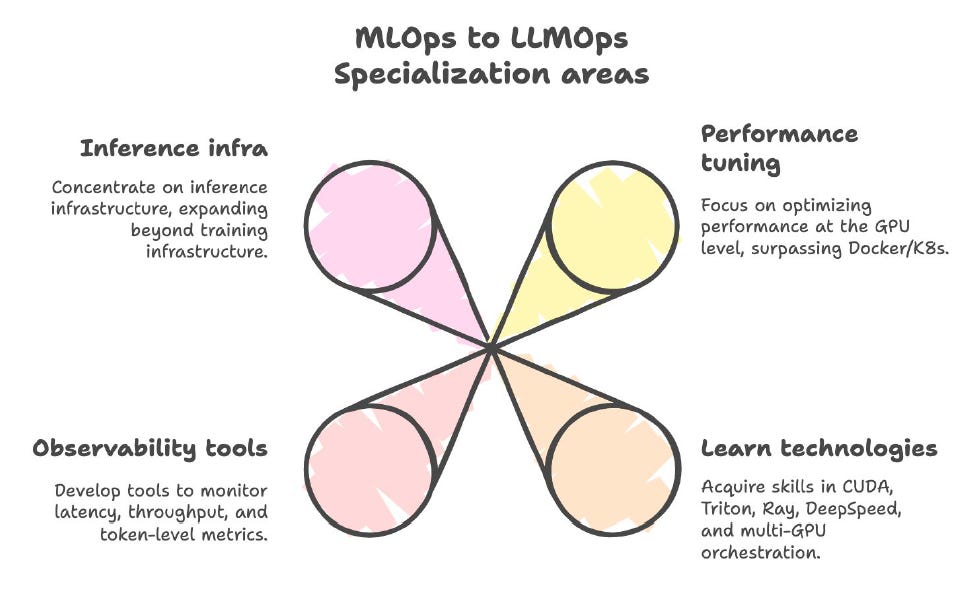
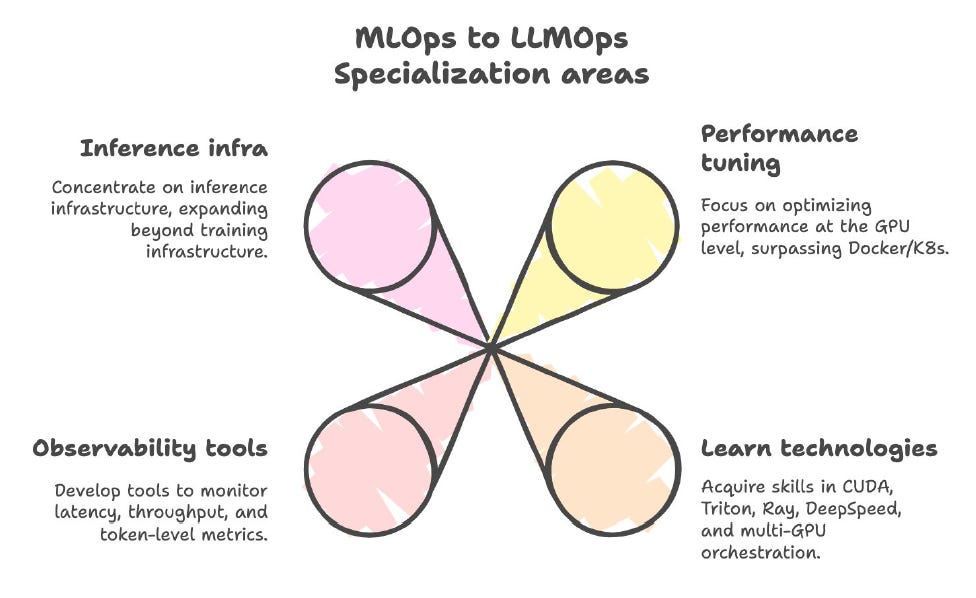
LLMOps Engineer
Skills: CUDA/Triton, Ray, latency optimization, observability for inference pipelines.
Why: Scaling LLM inference is a GPU + distributed systems challenge.
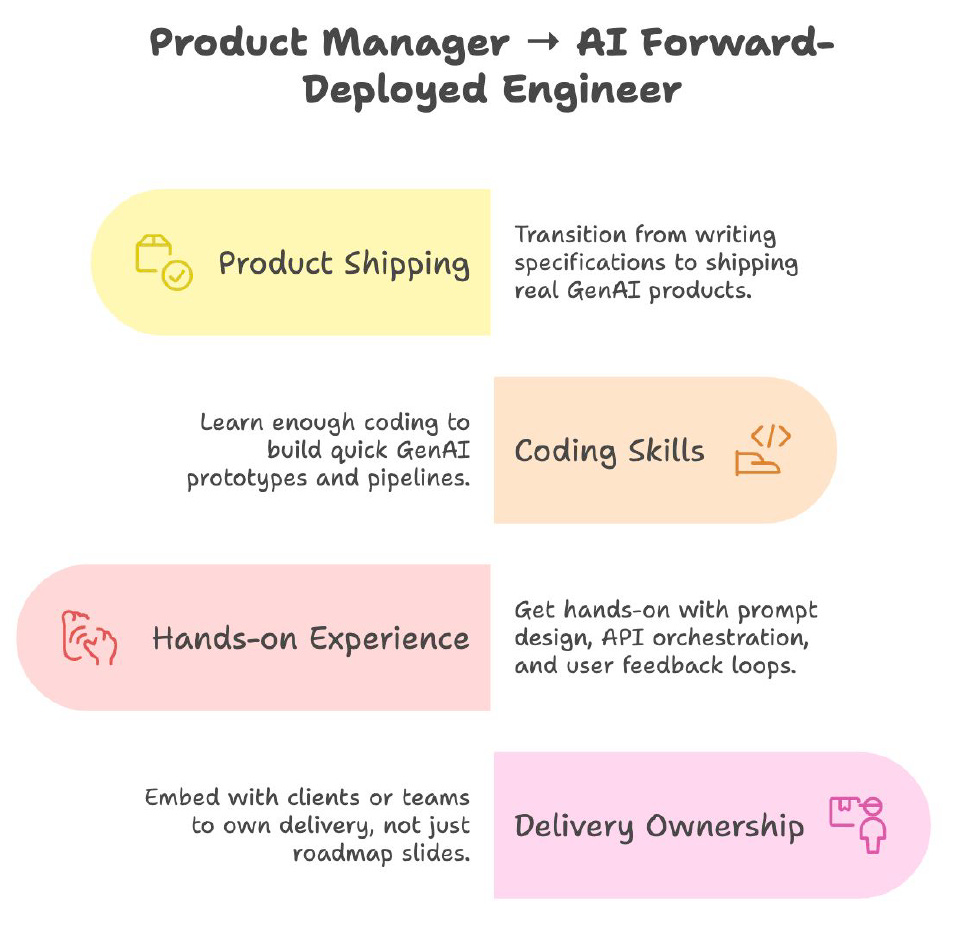
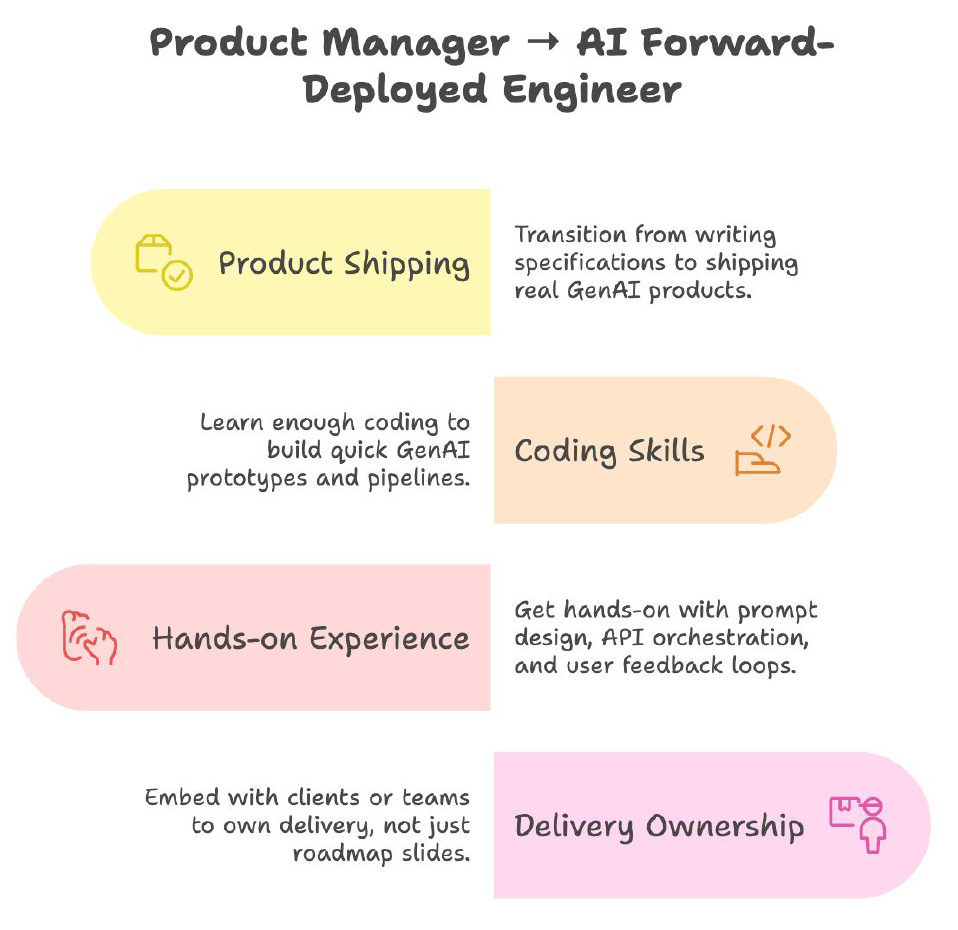
Forward-Deployed Engineer (FDE)
Skills: Hybrid PM + SWE, client-facing, embedding AI solutions into production environments.
Why: Prevents AI "proof of concept purgatory" by shipping real-world solutions.
Key Insight: These roles aren’t speculative. They exist right now across OpenAI, Nvidia, Palantir, and dozens of AI-first companies.
Biggest Gaps-
In totality, here are the largest missing skill gaps in the current market-
Learn inference stacks: vLLM, TensorRT-LLM, TGI, KV cache optimization.
Get GPU-fluent: CUDA, Triton, compiler basics, and kernel optimization.
Level up in orchestration: Ray, LangSmith, distributed inference frameworks.
Practice building RAG pipelines: Chunking, embeddings, eval sets, latency-aware design.
Adopt a systems mindset: Think beyond notebooks - production AI runs in distributed environments with tight latency constraints.
If you can bridge AI research and operational scale, you are unblockable in the market.
Final Words:
AI careers are shifting faster than ever. The gap isn’t in PhDs - it’s in engineers who can deploy and scale AI.
Over the next few weeks, I’ll be publishing deep dives into each of these four roles, along with hands-on skill-building guides.
→ Subscribe if you want the skills companies are hiring for right now.
PS: I am working on a course on AI Systems Engineering right now, and opening a waitlist/signups for the same time next week on Maven. I will be announcing it on LinkedIn and Twitter first so you can follow me there to stay on top of it (I am more active on LinkedIn when it comes to posting, lately).
Also, I update all my upcoming talks and events on my academic website so that’s a good place to keep for non-Maven events as well!
Until next time!
Cheers,
Abi